
DeepSeek流量暴跌?AI大模型霸主遇冷背后的真相
一度以“低价高性能”在全球AI圈引发轰动的中国大模型DeepSeek,为何最近在自家平台用户流失、市场份额下滑?这背后,隐藏着“Token经济学”的深层逻辑和一场战略转型,正悄然重塑AI的价值链与分发模式。

全球AI大战一触即发——GPT-5、Grok 4、Claude等新品消息不断,而DeepSeek也被传出有新模型即将亮相。许多人好奇,曾经攒足人气的DeepSeek R1,如今发展如何?
自发布超过150天以来,DeepSeek R1凭借媲美OpenAI的推理能力及不足十分之一的价格,一度撼动西方资本市场。但目前,DeepSeek在自家官网流量和用户黏性均出现了明显下滑,仿佛昙花一现后迅速沉寂。

DeepSeek真的衰落了吗?
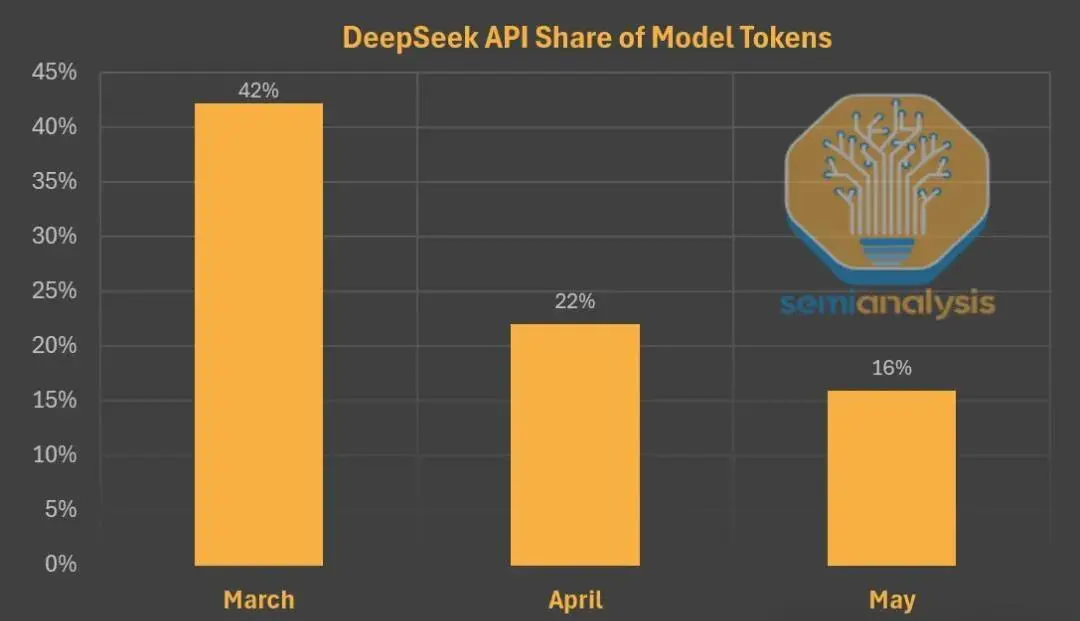
表面数据或许如此,但背后还有另一条增长曲线正在悄悄上升。在第三方平台上,R1的调用量爆发式成长——自首次发布以来,增长接近20倍。这实际反映出AI模型价值分发和生态结构发生的变革。
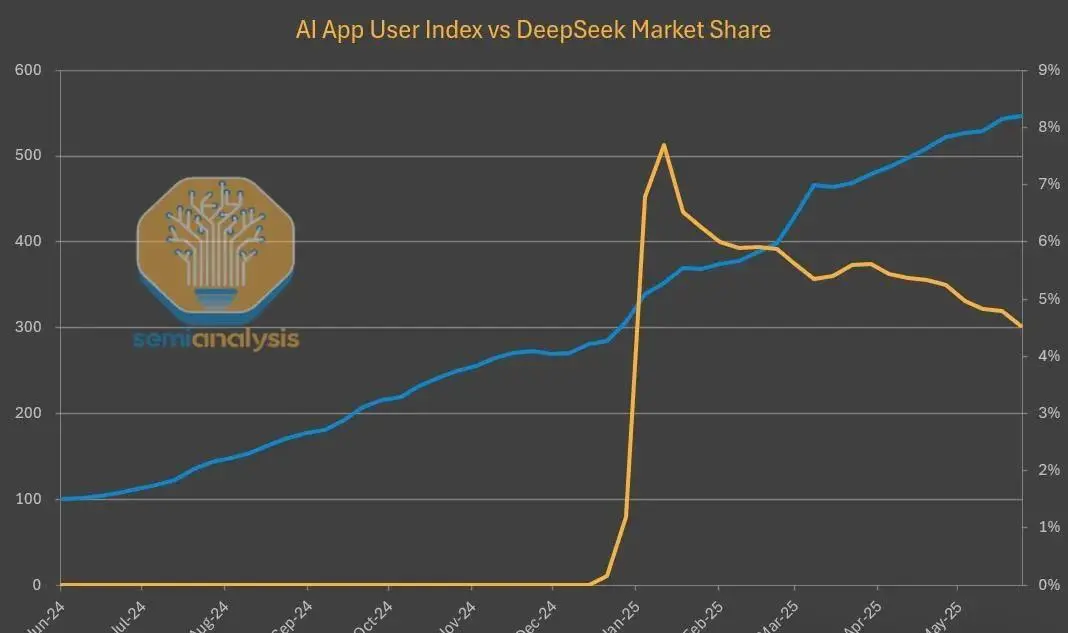
SemiAnalysis披露的内幕数据显示,尽管中国本土用户数据难追踪,DeepSeek自己的托管服务流量一度飙升,但其增速显著滞后于其他AI应用,市场份额持续下降。尤其在网页端和API的官方流量逐步走低时,第三方云服务商却托管着越来越多DeepSeek模型,用户活跃度火热。
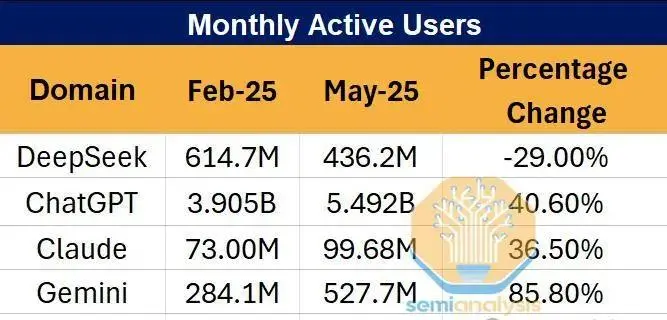
为何模型本身受欢迎、价格又极低,却用户从DeepSeek自营渠道流失,反而转投其他开放平台?核心答案在于“Token经济学”以及围绕性能、成本和体验等多维KPI之间的权衡。
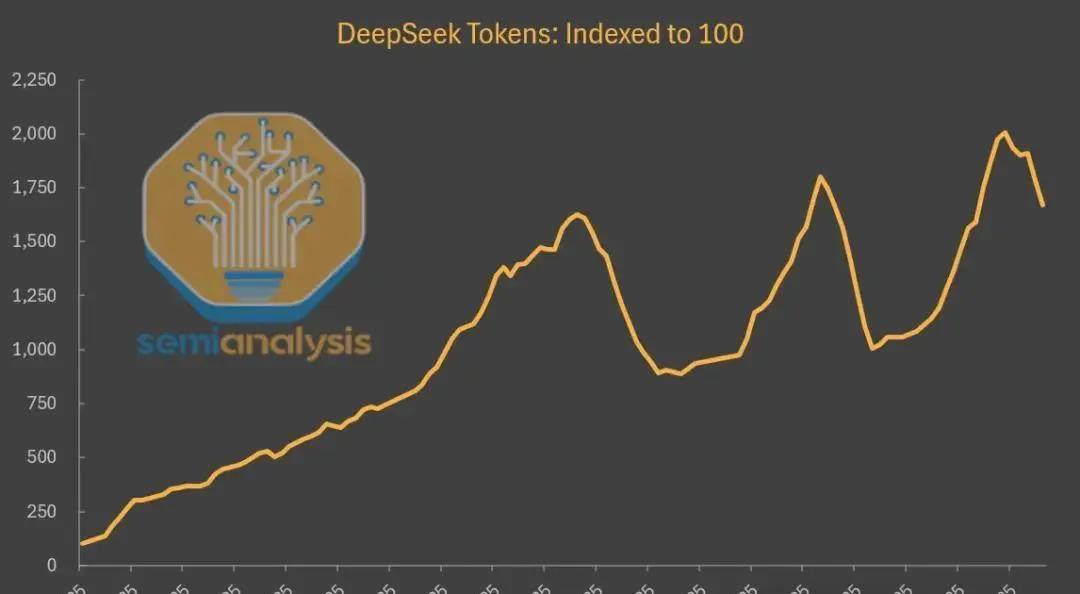
什么是Token经济学?
Token(令牌)是大模型运算与学习的基本单元。每个Token就像文本的小片段(如“fan”、”tas”、”tic”),大模型通过处理海量Token进行推理、生成和响应。对于服务商而言,盈利公式简单粗暴:“P x Q”——Token单价乘以Token数量。但与传统产品不同,Token的价格是灵活可调的,取决于延迟、吞吐速度、上下文窗口等关键性能指标(KPI),比如:
首Token延迟:输入请求到输出第一个Token的等待时间。DeepSeek为压低价格,采取了高批量处理策略,用户需等待更久才能得到第一个回应;
吞吐速率:单位时间内生成Token数量;
上下文窗口大小:模型短期记忆容量,影响对长文本、复杂代码的分析能力。
这些KPI决定了Token价格并非越低越优,而要综合考量具体应用需求和用户体验。
DeepSeek的权衡与策略
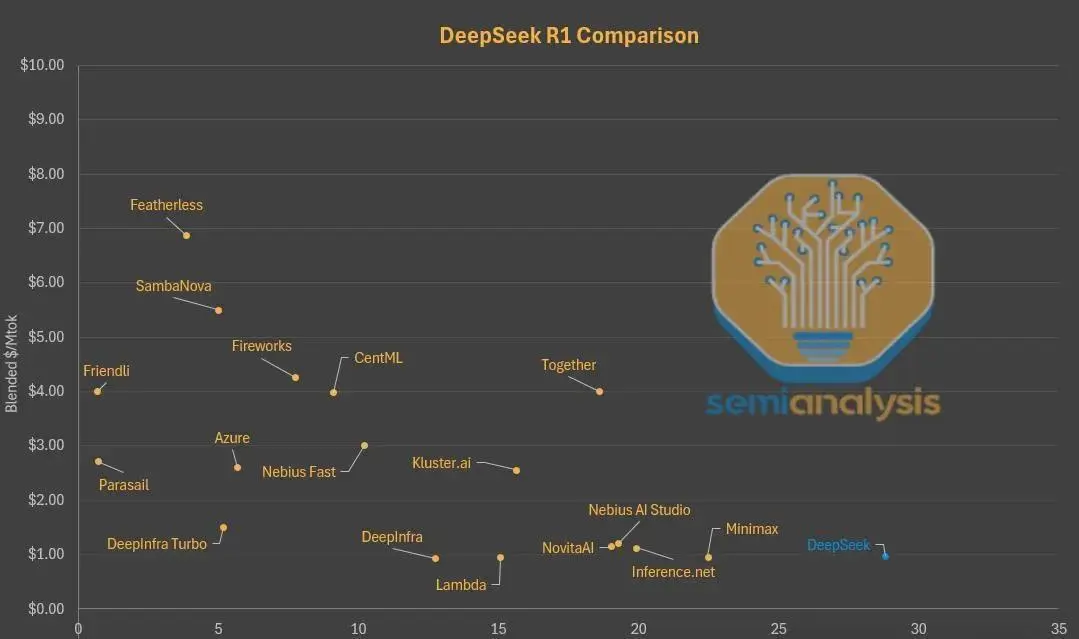
为何DeepSeek在自己的平台上逐渐失去市场?原因正是其“低价”的背后,是牺牲了响应速度和上下文窗口大小等体验,用极高的批量处理换取硬件成本最低。但这导致用户拿着便宜却不得不忍受较高延迟,以及远小于同类产品的上下文窗口,对编程等场景极为不友好。
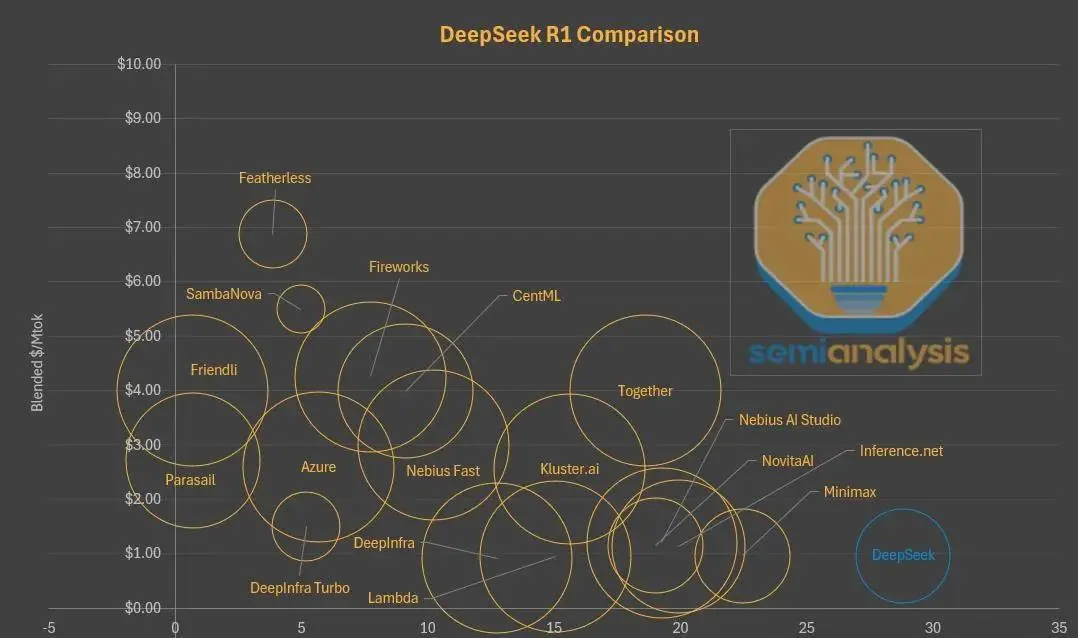
如今,在Parasail、Friendli等第三方平台,用户用类似价格就能获得几乎零延迟的体验;在Lambda、Nebius等处,还能获得更大的上下文窗口。因此,越来越多用户选择通过这些平台访问DeepSeek模型,而非其自家API和网页。
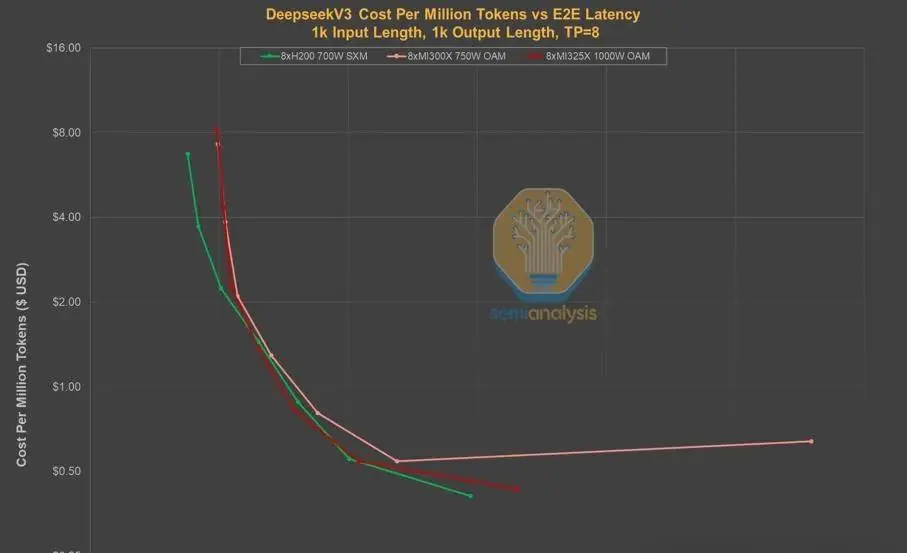
实际上,这是一种主动的战略转型。DeepSeek并不把终端用户体验作为首要目标,而是专注将有限算力用于AGI研发,把托管推理服务交给第三方,以提高全球知名度并快速拓展用户基础。对DeepSeek来说,将算力资源留给自研才最有价值。
此外,中外出口和监管也制约了中国AI公司在模型服务上的能力。开源、交由更多云厂商分发,成为合理路径。这并未削弱中国公司的训练实力,各大企业依然在积极推新模型。

其他厂商同样“算力焦虑”?
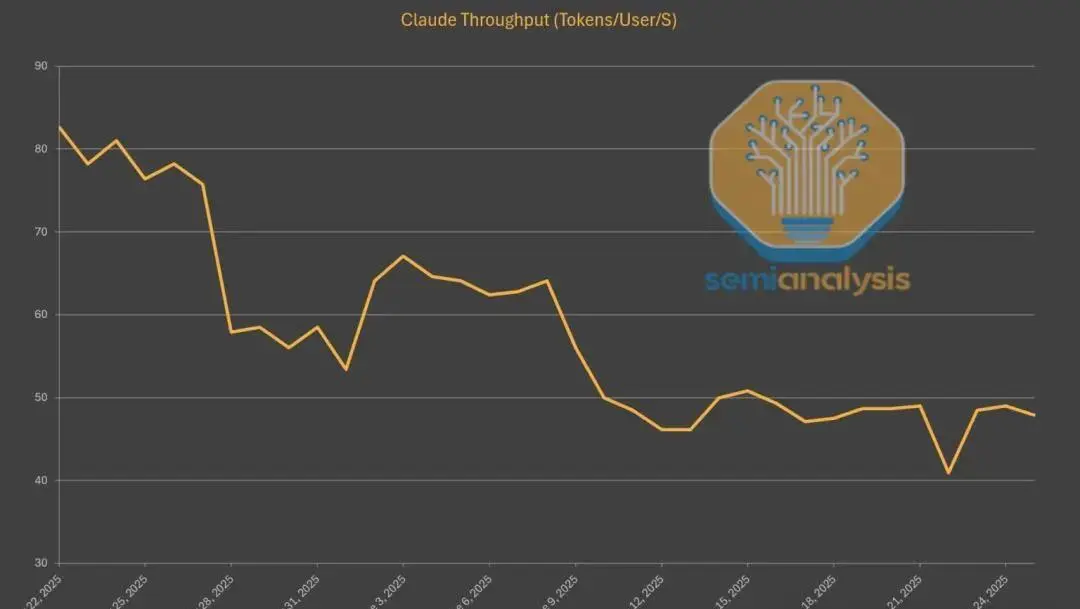
Anthropic的Claude系列也存在类似问题。因算力有限,Claude的API响应速度持续下降——最新Sonnet版本相比刚上线已慢了40%,只能靠加快批处理来缓解压力。而用户量激增,长对话和大Token需求,进一步放大了算力压力。
为此,Anthropic也与亚马逊签约获取50万颗Trainium芯片,试图补齐算力短板。
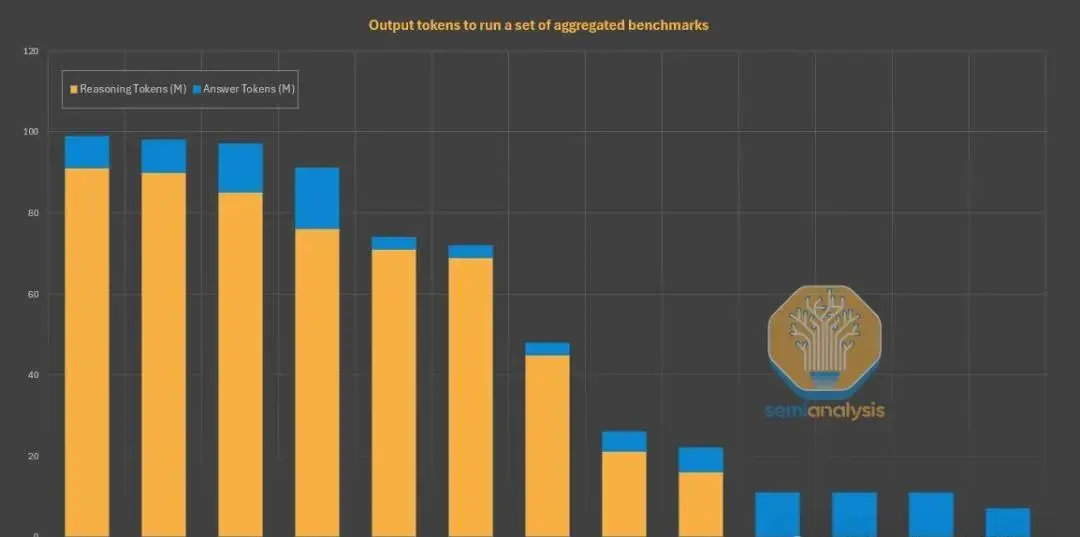
值得注意的是,Claude尽管速度劣势明显,却反而因“高效输出”获得良好体验:Claude平均生成内容字数比同类少得多,不啰嗦,用户端到端感受好。AI服务商都在努力提升“每单位Token承载的智能”,不再盲目追求低价和大包月,而是向Token即服务的细分计费、精细体验转型。
结语
DeepSeek流量下滑表象之下,是AI生态新格局的真实写照:低价只是一时利器,Token经济学与资源权衡才决定了竞争赛道。无论是自有平台还是第三方,“AI工厂”的价值链已全面开启重构。随着Cursor、Windsurf、Replit、Perplexity等“GPT套壳”应用流行,行业正从“大模型拼参数”转向“Token驱动生态”的新阶段。